[Oracle Database] join, union, subquery...
JOIN
JOIN은 테이블간 논리적인 관계를 바탕으로 두 개 이상의 테이블 컬럼을 동시에 가져오는 기술로, 하나의 테이블만으로 정보조회가 불가능한 경우 테이블들의 관계를 이용하여 원하는 데이터를 조회할 때 사용된다.
교차 조인, CROSS JOIN
조합 가능한 모든 경우를 조회하는 조인 방식 n * n. 단순 조인이라고도 한다.
SELECT 컬럼 FROM 테이블1 JOIN 테이블2 -- 명시적 표현
SELECT 컬럼 FROM 테이블1, 테이블2 -- 암묵적 표현
SELECT b.deptno, b.dname, a.empno, a.ename
FROM emp a, dept b
ORDER BY b.deptno, a.empno

위처럼 테이블간 관계를 WHERE절에 명시하지 않을 경우 emp 14행과 dept 4행의 모든 레코드를 1:1 매핑, 14 * 4 = 56 행을 출력. Cartesian Product 라고도 한다.
내부 조인, inner join
교차 조인에서 두 테이블에서 동시에 조인 조건을 만족하는 행만 가져온다.
SELECT 컬럼
FROM 테이블1 INNER JOIN 테이블2
ON 테이블1.컬럼 연산자 테이블2.컬럼 -- 명시적 표현, 'INNER JOIN'에서 'INNER'는 생략 가능하다.
SELECT 컬럼
FROM 테이블1, 테이블2
WHERE 테이블1.컬럼 연산자 테이블2.컬럼 -- 암묵적 표현
SELECT b.deptno, b.dname, A.empno, A.ename
FROM emp A JOIN dept b ON A.deptno = b.deptno
ORDER BY b.deptno, a.empno; -- 명시적 표현
SELECT b.deptno, b.dname, a.empno, a.ename
FROM emp a, dept b WHERE a.deptno = b.deptno
ORDER BY b.deptno, a.empno -- 암묵적 표현
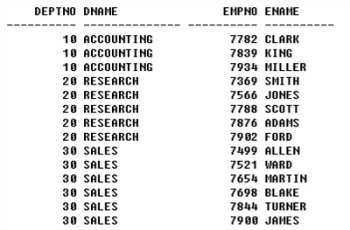
각 직원이 근무하는 부서의 이름을 표현한 SQL dept / emp 테이블은 deptno를 통하여 연결되며, 해당 조건을 on절(where절)에 명시.
내부 조인은 보통 1:N 관계테이블에서 사용되며 N:N 관계의 테이블에서는 중복값이 증가한다. N:N 관계의 테이블을 조인할 경우엔 연결된 컬럼을 조건절에 모두 명시해야 한다.
범위조건을 통한 조인
SELECT e.empno, e.ename, e.JOB, e.sal, s.grade
FROM emp e JOIN salgrade s
ON e.sal BETWEEN s.losal AND s.hisal
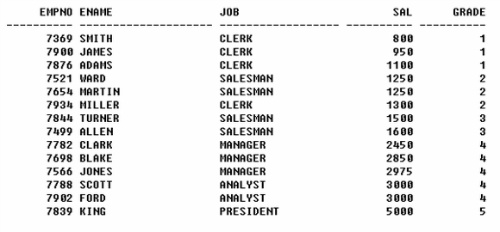
여기서 salgrade 테이블은 다음과 같다.
GRADE LOSAL HISAL
---------------------------------
1 700 1200
2 1201 1400
3 1401 2000
4 2001 3000
5 3001 9999
emp 테이블의 sal 값이 salgrade 테이블의 losal과 hisal 값 사이에 존재하면(between) 매핑하는 방식. 이와 같은 방식을 equi join이라고 하며 반대의 경우 non-equi join이라 한다.
3개 이상의 테이블을 조인할 때
SELECT * FROM VIDEO A
JOIN RENT B ON A.SEQ = B.WHAT
JOIN MEMBER C ON B.WHO = C.SEQ;
SELECT * FROM VIDEO A
JOIN RENT B ON A.SEQ = B.WHAT
JOIN MEMBER C ON B.WHO = C.SEQ
JOIN GENRE D ON A.GENRE = D.NAME;
외부 조인, outer join
교차 조인에서 두 테이블 중 하나를 지정해, 지정된 테이블은 일단 모든 레코드를 반환하고 지정되지 않은 테이블의 데이터는 먼저 반환된 테이블과 매핑한 결과만 가져온다. 교차 조인의 레코드에서 쓸모없는 레코드는 삭제하되, 기준이 된 테이블의 레코드는 제외하는 조인방법.
SELECT 컬럼
FROM 테이블1 [ LEFT | RIGHT | FULL ] OUTER JOIN 테이블2
ON 테이블1.컬럼 = 테이블2.컬럼
-- 'OUTER'는 생략 가능
SELECT E.employee_id, E.first_name || ' ' || E.last_name, nvl(D.department_name, '수습사원')
FROM employees E LEFT JOIN departments D
ON E.department_id = D.department_id

kimberely grant는 부서가 없기 때문에 내부 조인으로는 출력할 수 없다.
외부 조인의 암묵적 표현
SELECT d.deptno, e.empno, e.ename
FROM emp e, dept d
WHERE e.deptno(+) = d.deptno -- RIGHT JOIN, dept 테이블이 기준
ORDER BY d.deptno, e.empno;
SELECT d.deptno, e.empno, e.ename
FROM emp e, dept d
WHERE e.deptno = d.deptno(+) -- LEFT JOIN, emp 테이블 기준
ORDER BY d.deptno, e.empno;
명시적 표현과 반대 방향에 (+) 연산자를 표시한다. (LEFT JOIN이라면 오른쪽 테이블에 표시) 그리고 (+) 연산자는 양쪽 모두에 기술할 수 없다.
완전 외부 조인, full outer join
오른쪽 외부 조인과 왼쪽 외부 조인을 합친 개념. 왼쪽/오른쪽 테이블의 값이 일치하든 일치 하지 않든 모두 가져오는 조인이다. 교차 조인과 다른 점은 완전 외부 조인은 빈 값을 null 로 반환한다는 것이고 교차 조인은 양쪽 테이블을 그냥 단순히 연결시켜 준다는 점이다.
자가 조인, self join
특정조건에서 자신과 자신을 조인. 재귀참조 구조인 테이블에서만 가능하다. 오라클의 연습용 테이블인 emp에서 테스트 할 수 있다.
SELECT e1.ename, e2.ename
FROM emp e1 JOIN emp e2
ON e1.mgr = e2.empno
집합 연산자
UNION
둘 이상의 질의결과를 결합한다. 중복되는 데이터는 한 번만 출력한다.
-- 부서번호를 조회하는 UNION 예
SELECT deptno FROM emp
UNION
SELECT deptno FROM dept;
DEPTNO
--------
10
20
30
40
UNION은 UNION DISTINCT와 같은의미다.
UNION ALL
둘 이상의 질의결과를 결합한다. 중복되는 데이터는 반복 출력한다.
-- 부서번호를 조회하는 UNION ALL 예
SELECT deptno FROM emp
UNION ALL
SELECT deptno FROM dept;
DEPTNO
-------
20
30
30
20
30
...
18개의 행이 선택됨
INTERSECT
둘 이상의 질의결과에 공통적으로 존재하는 교집합을 출력
-- 부서번호를 조회하는 INTERSECT 예
SELECT deptno FROM emp
INTERSECT
SELECT deptno FROM dept;
DEPTNO
---------
10
20
30
MINUS
둘 이상의 질의 결과 중 선행 질의 결과에 대하여 후행 질의 결과를 제외한다.
-- 사원이 없는 부서를 조회하는 MINUS 예
SELECT deptno FROM dept
MINUS
SELECT deptno FROM emp;
DEPTNO
---------
40
subquery
질의를 통한 결과를 재사용하기 위하여 하나의 SQL 안에 포함된 SELECT 문장. Subquery는 각각 출력되는 결과에 따라 단일행/다중행, 단일컬럼/다중컬럼 Subquery로 구분된다. 하나의 질의안에 또 다른 질의의 결과값이 필요한 경우에 사용.
WHERE절 - subquery
select name, capital, popu
from country
where popu = (select max(popu) from country);
select * from insa
where city = (select city from insa where name='홍길동');
select * from insa
where substr(ssn, 1, 2) = (select substr(ssn, 1, 2) from insa where name = '홍길동');
select * from insa
where buseo in (select distinct buseo from insa where sudang >= 200000);
--emp 테이블에서 평균급여 이상의 급여를 받는 직원 조회
SELECT empno, ename, sal
FROM emp
WHERE sal > (SELECT AVG(sal) FROM emp);
--loc이 'DALLAS'인 데이터를 emp테이블과 dept테이블을 조인하여 출력
SELECT d.deptno, e.empno, e.ename
FROM emp e JOIN dept d
ON e.deptno = d.deptno
WHERE d.loc = 'DALLAS';
위를 서브쿼리로 처리하면 다음과 같다:
SELECT deptno, empno, ename
FROM EMP
WHERE deptno = (SELECT deptno FROM dept WHERE loc='DALLAS')
단, dept 테이블의 컬럼을 출력할 수 없는 것이 차이점.
ANY
하나라도 조건에 만족하면 TRUE
SELECT empno, ename, sal
FROM emp
WHERE sal > ANY(SELECT sal FROM emp WHERE deptno = 10)
부서번호 10에 해당하는 직원의 급여 중 하나보다 클 경우 만족. 즉, 최솟값보다 큰 급여를 받는 직원 조회
ALL
모든 조건에 만족해야 TRUE
SELECT empno, ename, sal
FROM emp
WHERE sal > ALL(SELECT sal FROM emp WHERE deptno = 10);
선택된 행 없음
여기서 dept 테이블은 다음과 같다:
SELECT sal, deptno FROM emp WHERE deptno = 10
SAL DEPTNO
---------- ----------
2450 10
5000 10
1300 10
이 경우엔 dept 테이블의 부서번호 10에 해당하는 직원들의 급여보다 크다는 조건이 모두 만족되어야 하니 최댓값보다 큰 급여를 받는 직원이 없어서 반환된 레코드가 없는것이다.
EXISTS / NOT EXISTS
하위 질의 값이 존재하면 TRUE
-- 상호관련하위질의의 한 예 : Main의 Alias가 Subquery에 참조됨
SELECT deptno, empno, ename
FROM emp e
where exists(select 1 from dept d where loc='DALLAS' and d.deptno=e.deptno);
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- ---------- --------- ---------- -------- ---------- ---------- ----------
7369 SMITH CLERK 7902 80/12/17 800 20
7566 JONES MANAGER 7839 81/04/02 2975 20
7788 SCOTT ANALYST 7566 87/04/19 3000 20
7876 ADAMS CLERK 7788 87/05/23 1100 20
7902 FORD ANALYST 7566 81/12/03 3000 20
FROM절 - 인라인 뷰 inline view
SELECT ename, sal, sal2
FROM (SELECT ename, sal, sal-(sal*0.04) AS sal2 FROM emp);
ENAME SAL SAL2
---------- ---------- ----------
SMITH 800 768
ALLEN 1600 1536
JAMES 950 912
FORD 3000 2880
MILLER 1300 1248
14개의 행이 선택됨
SELECT절 - 스칼라 서브쿼리 scalar subquery
Nested query라고도 하는 것 같음.
SELECT first_name, department_id,
(SELECT department_name FROM departments WHERE department_id = em.department_id) AS department_name
FROM employees em;
FIRST_NAME DEPARTMENT_ID DEPARTMENT_NAME
-------------------- ------------- ------------------------------
Donald 50 Shipping
Douglas 50 Shipping
Jennifer 10 Administration
Michael 20 Marketing
...
Kevin 50 Shipping
107개의 행이 선택됨
상관 서브쿼리 correlateds subquery
메인쿼리에 사용된 테이블의 컬럼이 서브쿼리의 조건절(where, having)에 사용되는 쿼리문
SELECT employee_id, first_name || ' ' || last_name, salary, department_id
,(SELECT count(*) FROM employees WHERE salary > M.salary ) + 1 AS "순위" --rank over
,(SELECT count(*) FROM employees WHERE department_id = M.department_id and salary > M.salary)
+ 1 AS "부서내순위" --partition by rank over
FROM employees M
ORDER BY 순위;
EMPLOYEE_ID FIRST_NAME||''||LAST_NAME SALARY DEPARTMENT_ID 순위 부서내순위
----------- ---------------------------------------------- ---------- ------------- ---------- ----------
100 Steven King 24000 90 1 1
101 Neena Kochhar 17000 90 2 2
102 Lex De Haan 17000 90 2 2
145 John Russell 14000 80 4 1
146 Karen Partners 13500 80 5 2
201 Michael Hartstein 13000 20 6 1
205 Shelley Higgins 12000 110 7 1
...
107개의 행이 선택됨
UPDATE employees M
SET first_name = (SELECT first_name FROM employees_backup WHERE employee_id = M.employee_id),
phone_number = (SELECT phone_number FROM employees_backup where employee_id = M.employee_id)
메모리에 최초로 올라간 메인쿼리(M)의 레코드들을 매번 읽을 때마다 서브쿼리의 결과를 가져와 수정을 하게 되는데, 이때 읽는 레코드 하나하나의 값을 비교하는것이 가능하다.
GROUP BY절의 확장
ROLLUP
기술한 COLUMN에 대하여 GROUP BY를 수행하며, 수행된 결과에 그룹별 집합 함수 정보를 추가한다.
-- emp 테이블에서 부서번호와 업무를 기준으로 평균급여 및 직원 수를 출력하며,
-- 부서번호별 평균급여 및 직원 수를 출력
SELECT deptno, job, COUNT(1), TRUNC(avg(sal))
FROM emp
GROUP BY ROLLUP(deptno, JOB)
ORDER BY deptno, JOB;
DEPTNO JOB TRUNC(AVG(SAL))
---------- --------- ---------------
10 CLERK 1300
10 MANAGER 2450
10 PRESIDENT 5000
10 2916
20 ANALYST 3000
20 CLERK 950
20 MANAGER 2975
20 2175
30 CLERK 950
30 MANAGER 2850
30 SALESMAN 1400
30 1566
2073
13개의 행이 선택됨
CUBE
기술한 COLUMN에 대하여 GROUP BY를 수행하며, 수행된 결과에 가능한 모든 집합 함수 정보를 추가한다.
-- EMP 테이블에서 부서번호와 업무를 기준으로 평균급여 및 직원 수를 출력하며,
-- 부서번호별, 업무별 평균급여 및 직원 수를 출력
SELECT deptno, JOB, count(1), TRUNC(AVG(sal))
FROM emp
GROUP BY CUBE(deptno, JOB)
ORDER BY deptno, JOB;
DEPTNO JOB COUNT(1) TRUNC(AVG(SAL))
---------- --------- ---------- ---------------
10 CLERK 1 1300
10 MANAGER 1 2450
10 PRESIDENT 1 5000
10 3 2916
20 ANALYST 2 3000
20 CLERK 2 950
20 MANAGER 1 2975
20 5 2175
30 CLERK 1 950
30 MANAGER 1 2850
30 SALESMAN 4 1400
30 6 1566
ANALYST 2 3000
CLERK 4 1037
MANAGER 3 2758
PRESIDENT 1 5000
SALESMAN 4 1400
14 2073
18개의 행이 선택됨
GROUP BY절이 1차원적 결과라면 ROLLUP은 2차원, CUBE는 3차원적 결과를 도출할 수 있도록 함.통계목적으로 주로 쓰임
ROLLUP/CUBE을 GROUPING SET으로 표현하기
ROLLUP(a, b, c) -> GROUPING SETS((a, b c), (a, b), (a), ())
CUBE(a, b, c) -> GROUPING SETS((a, b, c), (a, b), (a, c), (a, b), (a), (b), (c), ())
GROUPING SETS의 경우 위와 같이 표현 가능. 반대로 말하자면, 필요한 항목에 대해서만 정의가 가능 (ROLLUP / CUBE등을 통해 불필요한 항목까지 조회할 필요가 없다.)
SELECT deptno, JOB, count(1), TRUNC(AVG(sal))
FROM emp
GROUP BY GROUPING SETS(deptno, JOB)
ORDER BY deptno, JOB;
DEPTNO JOB COUNT(1) TRUNC(AVG(SAL))
---------- --------- ---------- ---------------
10 3 2916
20 5 2175
30 6 1566
ANALYST 2 3000
CLERK 4 1037
MANAGER 3 2758
PRESIDENT 1 5000
SALESMAN 4 1400
8개의 행이 선택됨
위와같이 부서번호와 업무에 대해서만 결과를 도출할 수 있다. 필요한 연산만 수행되므로, 질의문의 성능 개선도 기대할 수 있음. 단, ROLLUP / CUBE로 가능한 구문을 GROUPING SETS을 이용할 경우 사용은 편리하나, 성능이 떨어진다.
-- group by ROLLUP([컬럼]) : 집계함수의 총합계를 표시
-- GROUPING([컬럼]) : rollup 컬럼은 1, 그 외는 0으로 출력
SELECT
CASE WHEN GROUPING(department_id) = 0
THEN NVL(to_char(department_id), '인턴')
ELSE '전체부서' END as "부서번호"
, GROUPING(department_id), SUM(salary) AS 급여합
FROM EMPLOYEES
GROUP BY ROLLUP(department_id);
부서번호 GROUPING(DEPARTMENT_ID) 급여합
---------------------------------------- ----------------------- ----------
10 0 4400
20 0 19000
30 0 24900
40 0 6500
50 0 156400
60 0 28800
70 0 10000
80 0 304500
90 0 58000
100 0 51600
110 0 20300
인턴 0 7000
전체부서 1 691400
13개의 행이 선택됨