[Oracle Database] 함수 function
문자형 함수
LOWER, UPPER
대/소문자 변환
SELECT
LOWER('ABC'), -- 'abc'
UPPER('abc') -- 'ABC'
FROM dual
INITCAP
첫글자만 대문자로 변환
SELECT INITCAP('abc') FROM dual -- 'Abc'
SUBSTR
문자열에서 특정 위치 반환
SELECT SUBSTR('abcdefg', 2, 4) FROM dual; -- 'bcde'
SELECT SUBSTR('abcdefg', 2) FROM dual; -- 'bcdefg'
INSTR
문자열에서 특정 문자열의 인덱스값 반환. 찾지 못했을땐 0이 반환된다.
SELECT INSTR('abcdefg', 'ab') FROM dual; -- 1
SELECT INSTR('ABC정보통신 국가정보원 정보문화사', '정보', 1, 2) FROM dual; -- 11
--검색글자('정보'), 검색출발점(첫 번째 글짜부터) 두 번째 나오는 글자의 위치
--이 경우엔 '정보'가 셋 존재하는데 그 중 두 번째 정보의 인덱스값을 찾는 쿼리
LENGTH
문자열의 길이 구하기
SELECT LENGTH('abcdefg') FROM dual -- 7
LPAD/RPAD
문자열 좌/우 채우기
L/RPAD( str1, length, str2 )
str1의 길이에서 length를 뺀 나머지 길이만큼 str2로 채운다.
LPAD( str, length )
str의 길이에서 length를 뺀 나머지 길이만큼 공백으로 채운다.
SELECT
LPAD('haha', 8, '/'), -- '////haha'
RPAD('haha', 9, '*') -- 'haha*****'
FROM dual
TRIM/LTRIM/RTRIM
좌우/좌/우 공백 제거
SELECT
LTRIM(' nn '), -- 'nn '
RTRIM(' nn '), -- ' nn'
TRIM(' nn ') -- 'nn'
FROM dual;
SELECT RTRIM('인사부', '부') FROM DUAL; -- '인사', 문자열 오른쪽 끝에서 '부'를 찾아 지움
특정 문자를 지우는건 LTRIM, RTRIM만 가능하며 TRIM은 불가능
REPLACE
특정 문자 치환
SELECT
'test@naver.com', -- 'test@naver.com'
REPLACE('test@naver.com', 'naver.com', 'gmail.com') -- 'test@gmail.com'
FROM dual
REVERSE
문자열의 순서를 뒤집는다.
SELECT REVERSE('123456789') FROM dual; --987654321
SELECT SUBSTR(REVERSE('123456789'), 1, 3) FROM dual; --987
CONCAT
두 값을 연결한다(concatenation).
SELECT
CONCAT('A', 'BC'), -- 'ABC'
'A'||'BC' -- 'ABC'
FROM DUAL
ASCII / CHR
ASCII( A )
A의 아스키코드값을 구한다.
CHR( B )
아스키코드값 B의 문자를 구한다.
SELECT
ASCII('a'), -- 97
CHR(65) -- 'A'
FROM DUAL;
숫자형 함수
ROUND
반올림
ROUND( A )
B를 생략할 경우 소수점 첫째자리에서 반올림
ROUND( A, B )
A를 B 번째 소수점자리에서 반올림
SELECT
ROUND(1.39765, 2), -- 1.4
ROUND(1.39765) -- 1
FROM DUAL
TRUNC
TRUNC( A [, B] )
A를 소수점 자리 B+1부터 버린다. B를 생략할 경우 소수점 아래는 모두 버린다.
SELECT
TRUNC(1.39765, 4), -- 1.3976
TRUNC(1.39765) -- 1
FROM DUAL
CEIL
CEIL( A )
A의 소수점 이하를 올림.
SELECT CEIL(1.1919) FROM DUAL -- 2
FLOOR
FLOOR( A )
A의 소수점 이하를 내림.
SELECT FLOOR(1.1919) FROM DUAL -- 1
MOD
MOD( A, B )
A를 B로 나눈 나머지(나누지 못하면 A 반환).
SELECT MOD(6, 3) FROM DUAL -- 0
ABS
ABS( A )
A의 절댓값 반환.
SELECT ABS(-11) FROM DUAL -- 11
SQRT
SQRT( A )
A의 제곱근 반환.
SELECT SQRT(121) FROM DUAL -- 11
SIGN
SIGN( A )
A의 부호를 반환(1, -1, 0)
SELECT SIGN(-8) FROM DUAL -- -1
POWER
POWER( A, B )
A의 B제곱을 구한다.
SELECT POWER(2, 6) FROM DUAL
날짜형 함수
SYSDATE
현재 시각 구하기
SELECT SYSDATE FROM DUAL -- 2013-07-09 15:57:56.0
ADD_MONTHS
ADD_MONTHS( A, B )
A 값에 B만큼 월수를 더함. A는 날짜형 데이터만 가능.
SELECT ADD_MONTHS(SYSDATE, 4) FROM DUAL; -- 2013-11-09 16:06:39.0
SELECT ADD_MONTHS(TO_DATE('20130101 131313', 'YYYYMMDD HH24MISS'), 1) FROM DUAL; -- 2013-02-01 13:13:13.0
MONTHS_BETWEEN
MONTHS_BETWEEN( A, B )
A에서 B까지의 기간을 월로 반환한다. 날짜값의 +연산은 일자계산을 기준으로 한다.
SELECT MONTHS_BETWEEN(SYSDATE, SYSDATE+365) FROM DUAL -- -12
NEXT_DAY
NEXT_DAY( A, B )
A를 기준으로 명시된 요일(B)이 돌아오는 날짜를 구한다.
SELECT NEXT_DAY(SYSDATE, 1) FROM DUAL -- 2013-07-14 16:17:27.0
각 요일별 숫자
- SUNDAY: 1
- MONDAY: 2
- TUESDAY: 3
- WEDNESDAY: 4
- THURSDAY: 5
- FRIDAY: 6
- SATURDAY: 7
LAST_DAY
해당 월의 마지막 일
SELECT LAST_DAY(SYSDATE) FROM DUAL -- 2013-07-31 16:15:36.0
EXTRACT
EXTRACT( A FROM B )
B에서 A를 추출.
SELECT EXTRACT(YEAR FROM TO_DATE('20130709', 'YYYYMMDD')) FROM DUAL -- 2013
A에 올 수 있는 키워드: YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, TIMEZONE_HOUR, TIMEZONE_MINUTE, TIMEZONE_REGION, TIMEZONE_ABBR
타입 변환 함수
TO_NUMBER
문자열을 숫자형식으로 변환
SELECT TO_NUMBER('0123456') FROM DUAL -- 123456
TO_DATE
문자열 형식의 날짜값을 날짜형으로 변환
SELECT TO_DATE('20130101 131313', 'YYYYMMDD HH24MISS') FROM DUAL; -- 2013-01-01 13:13:13.0
SELECT TO_DATE('13/01/01 12:13:13', 'YY/MM/DD HH:MI:SS') FROM DUAL; -- 2013-01-01 12:13:13.0
포맷과 문자형식이 맞지 않으면 변환불가하다. 시, 분, 초 미지정시 00시, 00분, 00초로 설정됨. 일 미지정 시 1일. 월 미지정시 SYSDATE 기준 월. 년도 미지정 시 SYSDATE기준 년도.
TO_CHAR
숫자를 특정 형식의 문자로 변환
SELECT
TO_CHAR(12.4, '999.999'), -- 12.400
TO_CHAR(10, '000000'), -- 000010
TO_CHAR(200000, '999,999L') -- 200,000₩
FROM DUAL
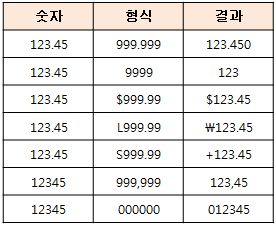
L: 지역화폐단위S: 부호
날짜를 특정 형식의 문자로 변환
SELECT TO_CHAR(SYSDATE, 'YYYY/MM/DD HH24:MI:SS') FROM DUAL; -- 2013/07/09 17:05:35
SELECT TO_CHAR(SYSDATE, 'YY-MM-DD HH-MI-SS') FROM DUAL; -- 13-07-09 05-05-47
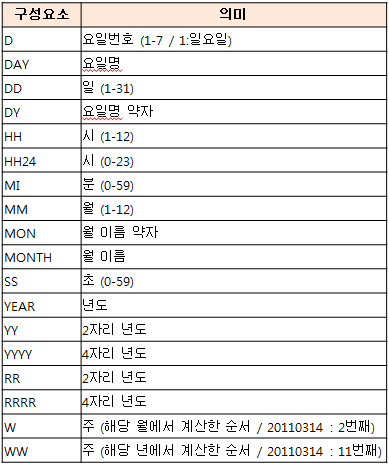
시간관련 형식 문자
AM,PM: 오전 또는 오후 표시A.M.,P.M.: 오전 또는 오후 표시HH12: 12시간으로 표시한다. HH와 같음SSSSS: 자정 이후 초(0~86399)
기타 형식 문자
/.,: 구분자 표시"of the": 결과에 추가할 문자열TH: 서수 표시 (DDTH → 4TH)SP: 영문 기수 표시 (DDSP → FOUR)SPTH,THSP: 영문 기수 표시 (DDSPTH → FOURTH)
날짜 데이터에서 특정값만 추출하는 방법
SELECT TO_CHAR(SYSDATE, 'yyyy'), -- 문자로 출력
EXTRACT(YEAR FROM SYSDATE), -- 숫자로 출력됨. 연산이 필요한 경우에 사용한다.
months_between('2013-03-02', '2010-12-25') -- 26.25806.. (정수는 월, 소수는 일)
FROM dual
TO_CHAR(SYSDATE,'YYYY') EXTRACT(YEARFROMSYSDATE) MONTHS_BETWEEN('2013-03-02','2010-12-25')
----------------------- ------------------------ -----------------------------------------
2013 2013 26.25806451612903225806451612903225806452
기타 함수
NVL
NVL( A, B )
A가 null이면 B로 출력.
NVL2( A, B, C )
A가 not null이면 B, null이면 C 출력
SELECT NVL(null, 79) FROM DUAL; -- 79
SELECT NVL2('im not null', 10101, 79) FROM DUAL; -- 10101
DECODE
DECODE( VALUE, A1, B1, A2, B2, A3, B3 ... )
VALUE가 A1이면 B1, A2면 B2, A3면 B3을 반환…
SELECT DECODE('DATA', 'DB', 'is DB', 'DATE', 'is DATE', 'neither') FROM DUAL -- neither
집합 함수 (그룹함수 또는 복수행함수)
SUM(value)
value의 합계
MAX(value)
최고값
MIN(value)
최솟값
AVG(value)
평균값
COUNT(column)
지정된 항목의 개수집합 함수 (그룹함수 또는 복수행함수)
SELECT COUNT(1), SUM(salary), MAX(salary), MIN(salary), AVG(salary)
FROM employees;
COUNT(1) SUM(SALARY) MAX(SALARY) MIN(SALARY) AVG(SALARY)
-------- ----------- ----------- ----------- -----------------------------------------
107 691416 24000 2100 6461.831775700934579439252336448598130841
--집합 함수는 null을 계산할 수 없다.
SELECT COUNT(salary), COUNT(commission_pct)
FROM employees;
COUNT(SALARY) COUNT(COMMISSION_PCT)
------------- ---------------------
107 35
SELECT AVG(commission_pct), AVG(NVL(commission_pct, 0))
FROM employees;
AVG(COMMISSION_PCT) AVG(NVL(COMMISSION_PCT,0))
------------------------------------------ -----------------------------------------
0.22285 0.07289
example: 부서별 직원 수, 평균급여 구하기
--GROUP BY절을 이용하여 기준이 되는 PATITION을 정하여 각각의 평균을 구할 수 있다.
--GROUP BY절을 이용할 시 SELECT 절에는 GROUP BY절에 사용한 단일 항목만 사용할 수 있다.
SELECT deptno, COUNT(*), ROUND(AVG(sal), 1)
FROM emp
GROUP BY deptno;
DEPTNO COUNT(*) ROUND(AVG(SAL),1)
------ -------- -----------------
30 6 1566.7
20 3 2258.3
10 3 2916.7
example: emp 테이블에서 부서별 직원 수가 5 이상의 부서의 직원수 및 평균급여
--집합함수를 조건으로 사용할 경우 WHERE절에 사용할 수 없다
--HAVING절을 사용하여 GROUP BY에 대한 조건을 명시할 수 있다
SELECT deptno, COUNT(*), ROUND(AVG(sal), 1)
FROM emp
GROUP BY deptno
HAVING COUNT(*) >= 5;
DEPTNO COUNT(*) ROUND(AVG(SAL),1)
------ -------- -----------------
30 6 1566.7
집계(혹은 분석) 함수
ROW_NUMBER() OVER()
조건을 통하여 고유한 서수를 반환.
부서별 급여 순위 조회
같은 부서 내PARTITION BY deptno에서 급여순 정렬ORDER BY sal DESC 후 서수ROW_NUMBER()를 적용:
SELECT deptno, empno, ename, sal,
ROW_NUMBER() OVER(PARTITION BY deptno ORDER BY sal DESC) AS rnk
FROM EMP
ORDER BY deptno, sal DESC;
DEPTNO EMPNO ENAME SAL RNK
------ ----- ------ ---- ---
10 7839 KING 5000 1
10 7782 CLARK 2450 2
10 7934 MILLER 1300 3
20 7902 FORD 3000 1
20 7566 JONES 2975 2
20 7369 SMITH 800 3
30 7698 BLAKE 2850 1
...
급여 순위 조회
분석함수는 PARTITION BY를 생략하고 사용하는 경우도 있다.
급여순으로 정렬ORDER BY sal DESC 후 서수(ROW_NUMBER())를 적용:
SELECT deptno, empno, ename, sal,
ROW_NUMBER() OVER(ORDER BY sal DESC) AS rnk
FROM EMP
ORDER BY rnk;
DEPTNO EMPNO ENAME SAL RNK
---------- ---------- ---------- ---------- ----------
10 7839 KING 5000 1
20 7902 FORD 3000 2
20 7566 JONES 2975 3
30 7698 BLAKE 2850 4
10 7782 CLARK 2450 5
30 7499 ALLEN 1600 6
...
ROW_NUMBER()를 이용한 pagination
SELECT *
FROM (
SELECT ROW_NUMBER() OVER(ORDER BY boardNum DESC) rnum,
boardNum, name, subject, hitCount,
TO_CHAR(created, 'yyyy-mm-dd') as created
FROM bbs
)
WHERE rnum >= #{start} AND rnum <= #{end}
#{뿅뿅}: Java 마이바티스 매개변수
FIRST_VALUE() OVER()
조건을 통하여 조회된 값 중 첫 번째 값을 반환
부서별 최고 급여 조회
같은 부서 내PARTITION BY deptno에서 급여순 정렬ORDER BY sal DESC 후 가장 처음의 급여FIRST_VALUE(sal) 조회:
SELECT deptno, empno, ename, sal,
FIRST_VALUE(sal) OVER(PARTITION BY deptno ORDER BY sal DESC) AS max_sal
FROM emp
ORDER BY deptno, empno;
DEPTNO EMPNO ENAME SAL MAX_SAL
---------- ---------- ---------- ---------- ----------
10 7782 CLARK 2450 5000
10 7839 KING 5000 5000
10 7934 MILLER 1300 5000
20 7369 SMITH 800 3000
20 7566 JONES 2975 3000
20 7902 FORD 3000 3000
30 7499 ALLEN 1600 2850
...
COUNT() OVER()
조건을 통하여 누적 COUNT 수 반환.
부서별 누적 건수 조회
같은 부서 내PARTITION BY deptno에서 급여순 정렬ORDER BY sal 후 누적 건수COUNT(*) 조회. 여기서 '누적 건수'는 서수와 같다고 봐도 된다:
SELECT deptno, empno, ename, sal,
COUNT(*) OVER(PARTITION BY deptno ORDER BY sal) AS cnt
FROM emp
ORDER BY deptno, sal;
DEPTNO EMPNO ENAME SAL CNT
---------- ---------- ---------- ---------- ----------
10 7934 MILLER 1300 1
10 7782 CLARK 2450 2
10 7839 KING 5000 3
20 7369 SMITH 800 1
20 7566 JONES 2975 2
20 7902 FORD 3000 3
30 7900 JAMES 950 1
...
직업별 누적 건수 조회
ORDER BY도 PARTITION BY처럼 경우에 따라 없이 사용하기도 한다. COUNT(*) OVER()의 경우 ORDER BY를 생략하면 누적 건수가 아니라 PARTITION BY로 지정된 컬럼별 전체 건수를 계산한다:
SELECT job ,ename,
COUNT(*) OVER(PARTITION BY job)
FROM emp;
JOB ENAME COUNT(*)OVER(PARTITIONBYJOB)
--------- ---------- ----------------------------
ANALYST FORD 1
CLERK MILLER 3
CLERK JAMES 3
CLERK SMITH 3
MANAGER JONES 3
MANAGER BLAKE 3
MANAGER CLARK 3
PRESIDENT KING 1
SALESMAN TURNER 4
SALESMAN WARD 4
SALESMAN ALLEN 4
SALESMAN MARTIN 4
12개의 행이 선택됨
SUM() OVER()
조건을 통하여 누적된 값의 합을 반환
부서별 누적급여 조회
같은 부서 내PARTITION BY deptno의 급여의 합SUM(sal)을 계산하되, 사번 순ORDER BY empno으로 누적치를 표시한다:
SELECT deptno, empno, ename, sal,
SUM(sal) OVER(PARTITION BY deptno ORDER BY empno) AS sum_sal
FROM emp;
DEPTNO EMPNO ENAME SAL SUM_SAL
---------- ---------- ---------- ---------- ----------
10 7782 CLARK 2450 2450
10 7839 KING 5000 7450
10 7934 MILLER 1300 8750
20 7369 SMITH 800 800
20 7566 JONES 2975 3775
20 7902 FORD 3000 6775
30 7499 ALLEN 1600 1600
...
RANK() OVER(조건)
조건을 통해 순위를 반환한다. 해당 조건을 만족하면서 동일한 값이 있는 경우 동일 순위로 매겨지며, 다음 순위는 동일한 값이 있는 만큼 증가(2위가 두 명이면 다음 순위는 4위)한다.
부서별 급여순위(내림차순) 조회
# 등록일시 순으로 순위 매기기(가장 빠르게 등록된 데이터가 1위)
select rank() over(order by createDt) from someTable;
# 같은 부서 내`PARTITION BY deptno`에서 급여가 많은 순`ORDER BY sal DESC`으로 순위`RANK()` 표시
SELECT deptno, empno, ename, sal,
RANK() OVER(PARTITION BY deptno ORDER BY sal DESC) AS RK
FROM emp
ORDER BY deptno, sal DESC;
DEPTNO EMPNO ENAME SAL RK
---------- ---------- ---------- ---------- ----------
...
30 7499 ALLEN 1600 1
30 7844 TURNER 1500 2
30 7521 WARD 1250 3
30 7654 MARTIN 1250 3
30 7900 JAMES 950 5
ROW_NUMBER()와의 차이
순위 매기는 방식이 다르다:
-- COUNT 값 같아도 동순위 없이 ROWNUM 우선해서 순위 매김
SELECT MEMBER_NO, CNT, ROW_NUMBER() OVER(ORDER BY CNT DESC) RN
FROM (
SELECT MEMBER_NO, COUNT(*) CNT
FROM EVENT_PARTICIPANT
WHERE EVENT_NO = '00000000007823'
GROUP BY MEMBER_NO
);
-- COUNT 값 같으면 동순위로 표시
SELECT MEMBER_NO, CNT, RANK() OVER(ORDER BY CNT DESC) RN
FROM (
SELECT MEMBER_NO, COUNT(*) CNT
FROM EVENT_PARTICIPANT
WHERE EVENT_NO = '00000000007823'
GROUP BY MEMBER_NO
);
DENSE_RANK() OVER(조건)
조건을 통해 순위를 반환한다. 해당 조건을 만족하면서 동일한 값이 있는 경우 동일 순위로 매겨지며, 다음 순위는 1만큼 증가한다(2위가 두 명이어도 다음 순위는 3위).
부서별 급여순위(내림차순) 조회
같은 부서 내PARTITION BY deptno에서 급여가 많은 순ORDER BY sal DESC으로 순위DENSE_RANK() 표시:
SELECT deptno, empno, ename, sal,
DENSE_RANK() OVER(PARTITION BY deptno ORDER BY sal DESC) AS RK
FROM emp
ORDER BY deptno, sal DESC;
DEPTNO EMPNO ENAME SAL RK
---------- ---------- ---------- ---------- ----------
...
30 7698 BLAKE 2850 1
30 7499 ALLEN 1600 2
30 7844 TURNER 1500 3
30 7521 WARD 1250 4
30 7654 MARTIN 1250 4
30 7900 JAMES 950 5
그 외 분석 함수
- AVG
- CORR
- COVAR_POP
- COVAR_SAMP
- CUME_DIST
- FIRST
- GROUP_ID
- GROUPING
- GROUPING_ID
- LAG
- LAST
- LAST_VALUE
- LEAD
- MAX
- MIN
- NTILE
- PERCENT_RANK
분석 함수의 OVER절 조건을 생략한 쿼리
-- 이름과 이름의 레코드 수만큼 avg(basicpay)를 출력한다.
SELECT NAME, AVG(BASICPAY) OVER() FROM INSA;