[Oracle Database] 쿼리 조각 모음
- 개요
- 프로시저 호출하기
- 딕셔너리를 활용해서 테이블 스키마 분석하기
- 개행문자 변환하기
- 컬럼 병합
- 유니코드 구분하기
- 날짜별 통계 + 컬럼 병합
- 년, 월을 입력받아 달력 출력
- 재귀 구조를 갖는 데이터의 경로 출력
- connect by로 날짜 데이터 만들기
- 다중 행을 하나의 행으로 출력
- 테이블 컬럼을 자바 필드로
개요
나중에 다시 쓸 것만 같은 쿼리 조각 모음.
프로시저 호출하기
이런 프로시저가 있을 때:
CREATE OR REPLACE PROCEDURE TEST_ME(
PARAMETER1 IN VARCHAR2,
RESULT OUT VARCHAR2
)
AS
BEGIN
RESULT := 'BEGIN';
DBMS_OUTPUT.PUT_LINE(PARAMETER1);
RESULT := 'END';
END;
/
아래처럼 호출하면:
DECLARE
RESULT VARCHAR2(100);
BEGIN
TEST_ME('hello!', RESULT);
DBMS_OUTPUT.PUT_LINE(RESULT);
END;
COMMIT;
요로코롬 찍힌다:
hello!
END
딕셔너리를 활용해서 테이블 스키마 분석하기
SELECT DISTINCT
ACC.COMMENTS AS COLUMNCOMMENT,
ATC.OWNER, ATC.TABLE_NAME, ATC.COLUMN_NAME, ATC.DATA_TYPE, ATC.DATA_LENGTH, ATC.NULLABLE, ATC.COLUMN_ID,
ATCMT.COMMENTS AS TABLECOMMENT,
CASE WHEN PKCOL.COLUMN_NAME IS NOT NULL THEN 'Y' ELSE 'N' END AS PRIMARY_KEY
FROM ALL_TAB_COLUMNS ATC
JOIN ALL_COL_COMMENTS ACC ON ATC.COLUMN_NAME = ACC.COLUMN_NAME AND ATC.TABLE_NAME = ACC.TABLE_NAME AND ATC.OWNER = ACC.OWNER
LEFT JOIN ALL_TAB_COMMENTS ATCMT ON ATCMT.TABLE_NAME = ATC.TABLE_NAME AND ATCMT.OWNER = ATC.OWNER
LEFT JOIN (
SELECT ACC.OWNER, ACC.TABLE_NAME, ACC.COLUMN_NAME
FROM ALL_CONS_COLUMNS ACC
JOIN ALL_CONSTRAINTS AC ON ACC.CONSTRAINT_NAME = AC.CONSTRAINT_NAME AND ACC.OWNER = AC.OWNER
WHERE AC.CONSTRAINT_TYPE = 'P'
) PKCOL ON ATC.OWNER = PKCOL.OWNER AND ATC.TABLE_NAME = PKCOL.TABLE_NAME AND ATC.COLUMN_NAME = PKCOL.COLUMN_NAME
WHERE ATC.TABLE_NAME = '테이블이름'
AND ATC.OWNER = '객체소유자이름'
ORDER BY ATC.COLUMN_ID;
테이블과 컬럼 코멘트, 데이터 타입, PK 여부 등을 조회한다.
개행문자 변환하기
REPLACE( REPLACE( DTL_DESC, CHR(10) ), CHR(13), '|')
컬럼 병합
방법 1. FULL JOIN
WITH TEMP1 AS (
SELECT 1 AS NO, 'AAA' AS NAME FROM DUAL UNION
SELECT 2 AS NO, 'BBB' AS NAME FROM DUAL UNION
SELECT 3 AS NO, 'CCC' AS NAME FROM DUAL
), TEMP2 AS (
SELECT 3 AS NO, 'C@C.COM' AS MAIL FROM DUAL UNION
SELECT 4 AS NO, 'D@D.COM' AS MAIL FROM DUAL UNION
SELECT 5 AS NO, 'E@E.COM' AS MAIL FROM DUAL
)
SELECT NVL(TEMP1.NO, TEMP2.NO) AS NO, NAME, MAIL
FROM TEMP1 FULL JOIN TEMP2 ON TEMP1.NO = TEMP2.NO
ORDER BY TEMP1.NO
방법 2. UNION
WITH TEMP1 AS (
SELECT 1 AS NO, 'AAA' AS NAME FROM DUAL UNION
SELECT 2 AS NO, 'BBB' AS NAME FROM DUAL UNION
SELECT 3 AS NO, 'CCC' AS NAME FROM DUAL
), TEMP2 AS (
SELECT 3 AS NO, 'C@C.COM' AS MAIL FROM DUAL UNION
SELECT 4 AS NO, 'D@D.COM' AS MAIL FROM DUAL UNION
SELECT 5 AS NO, 'E@E.COM' AS MAIL FROM DUAL
)
SELECT NO, MAX(NAME), MAX(MAIL)
FROM (
SELECT NO, NAME, '' AS MAIL
FROM TEMP1
UNION
SELECT NO, '' AS NAME, MAIL
FROM TEMP2
)
GROUP BY NO
ORDER BY NO
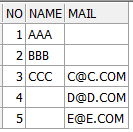
결과 예시
대상 1:
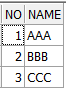
대상 2:

결과:
유니코드 구분하기
SELECT
WORD,
ASCIISTR(WORD) AS "TO ASCII",
LENGTH(ASCIISTR(WORD)) AS "LENGTH OF ASCII",
CASE
WHEN LENGTH(ASCIISTR(WORD)) > LENGTH(WORD) THEN 'IS UNICODE'
ELSE 'IS ASCII'
END AS "RESULT"
FROM (
SELECT 'ABCD' WORD FROM DUAL
UNION
SELECT '홀롤롤로' WORD FROM DUAL
);
ASCIISTR 함수는 Non-ASCII 문자를 \xxxx 형식의 UTF-16 코드로 반환한다. 이를 이용해서 유니코드인지 아스키인지 구분하는 쿼리.
날짜별 통계 + 컬럼 병합
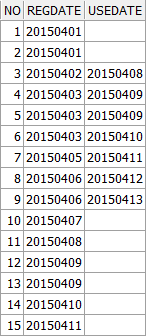
위와 같은 데이터가 있을 때 다음처럼 날짜별 통계 데이터를 출력하는 방법이다:

WITH TEMP AS (
SELECT 1 AS NO, '20150401' AS REGDATE, '' AS USEDATE FROM DUAL UNION
SELECT 2 AS NO, '20150401' AS REGDATE, '' AS USEDATE FROM DUAL UNION
SELECT 3 AS NO, '20150402' AS REGDATE, '20150408' AS USEDATE FROM DUAL UNION
SELECT 4 AS NO, '20150403' AS REGDATE, '20150409' AS USEDATE FROM DUAL UNION
SELECT 5 AS NO, '20150403' AS REGDATE, '20150409' AS USEDATE FROM DUAL UNION
SELECT 6 AS NO, '20150403' AS REGDATE, '20150410' AS USEDATE FROM DUAL UNION
SELECT 7 AS NO, '20150405' AS REGDATE, '20150411' AS USEDATE FROM DUAL UNION
SELECT 8 AS NO, '20150406' AS REGDATE, '20150412' AS USEDATE FROM DUAL UNION
SELECT 9 AS NO, '20150406' AS REGDATE, '20150413' AS USEDATE FROM DUAL UNION
SELECT 10 AS NO, '20150407' AS REGDATE, '' AS USEDATE FROM DUAL UNION
SELECT 11 AS NO, '20150408' AS REGDATE, '' AS USEDATE FROM DUAL UNION
SELECT 12 AS NO, '20150409' AS REGDATE, '' AS USEDATE FROM DUAL UNION
SELECT 13 AS NO, '20150409' AS REGDATE, '' AS USEDATE FROM DUAL UNION
SELECT 14 AS NO, '20150410' AS REGDATE, '' AS USEDATE FROM DUAL UNION
SELECT 15 AS NO, '20150411' AS REGDATE, '' AS USEDATE FROM DUAL
)
SELECT NVL(REGDATE, USEDATE), NVL(REG_CNT, 0), NVL(USE_CNT, 0)
FROM (
SELECT REGDATE, COUNT(REGDATE) AS REG_CNT
FROM TEMP
GROUP BY REGDATE
) A
FULL JOIN (
SELECT USEDATE, COUNT(USEDATE) AS USE_CNT
FROM TEMP
GROUP BY USEDATE
) B
ON A.REGDATE = B.USEDATE
ORDER BY REGDATE
별도의 날짜 데이터가 필요한 경우:
WITH days AS (
SELECT TO_CHAR(TO_DATE('20150401','yyyymmdd') + LEVEL - 1, 'yyyymmdd') AS DAY
FROM DUAL
CONNECT BY LEVEL <= TO_DATE('20150413','yyyymmdd') - TO_DATE('20150401','yyyymmdd') + 1
),
TEMP AS (
SELECT 1 AS NO, '20150401' AS REGDATE, '' AS USEDATE FROM DUAL UNION
SELECT 2 AS NO, '20150401' AS REGDATE, '' AS USEDATE FROM DUAL UNION
SELECT 3 AS NO, '20150402' AS REGDATE, '20150408' AS USEDATE FROM DUAL UNION
SELECT 4 AS NO, '20150403' AS REGDATE, '20150409' AS USEDATE FROM DUAL UNION
SELECT 5 AS NO, '20150403' AS REGDATE, '20150409' AS USEDATE FROM DUAL UNION
SELECT 6 AS NO, '20150403' AS REGDATE, '20150410' AS USEDATE FROM DUAL UNION
SELECT 7 AS NO, '20150405' AS REGDATE, '20150411' AS USEDATE FROM DUAL UNION
SELECT 8 AS NO, '20150406' AS REGDATE, '20150412' AS USEDATE FROM DUAL UNION
SELECT 9 AS NO, '20150406' AS REGDATE, '20150413' AS USEDATE FROM DUAL UNION
SELECT 10 AS NO, '20150407' AS REGDATE, '' AS USEDATE FROM DUAL UNION
SELECT 11 AS NO, '20150408' AS REGDATE, '' AS USEDATE FROM DUAL UNION
SELECT 12 AS NO, '20150409' AS REGDATE, '' AS USEDATE FROM DUAL UNION
SELECT 13 AS NO, '20150409' AS REGDATE, '' AS USEDATE FROM DUAL UNION
SELECT 14 AS NO, '20150410' AS REGDATE, '' AS USEDATE FROM DUAL UNION
SELECT 15 AS NO, '20150411' AS REGDATE, '' AS USEDATE FROM DUAL
), reg AS (
SELECT day, count(regdate) AS regcnt
FROM TEMP, days
WHERE temp.regdate(+) = days.day
GROUP BY days.day
), use AS (
SELECT day, count(usedate) AS usecnt
FROM TEMP, days
WHERE temp.usedate(+) = days.day
GROUP BY days.day
)
SELECT reg.day, reg.regcnt, use.usecnt
FROM reg, use
WHERE reg.day = use.day
ORDER BY reg.day
년, 월을 입력받아 달력 출력
SELECT
MIN (DECODE (TO_CHAR (DAYS, 'D'), 1, TO_CHAR (DAYS, 'FMDD'))) AS SUN,
MIN (DECODE (TO_CHAR (DAYS, 'D'), 2, TO_CHAR (DAYS, 'FMDD'))) AS MON,
MIN (DECODE (TO_CHAR (DAYS, 'D'), 3, TO_CHAR (DAYS, 'FMDD'))) AS TUE,
MIN (DECODE (TO_CHAR (DAYS, 'D'), 4, TO_CHAR (DAYS, 'FMDD'))) AS WED,
MIN (DECODE (TO_CHAR (DAYS, 'D'), 5, TO_CHAR (DAYS, 'FMDD'))) AS THU,
MIN (DECODE (TO_CHAR (DAYS, 'D'), 6, TO_CHAR (DAYS, 'FMDD'))) AS FRI,
MIN (DECODE (TO_CHAR (DAYS, 'D'), 7, TO_CHAR (DAYS, 'FMDD'))) AS SAT
FROM (
SELECT
BASE_MON + LEVEL - 1 AS DAYS,
(TRUNC(BASE_MON + LEVEL - 1, 'D') - TRUNC(TRUNC(BASE_MON + LEVEL - 1, 'Y'), 'D')) / 7 + 1 AS WEEK_GRP
FROM (
SELECT
TO_DATE (NVL(2017, TO_CHAR(SYSDATE, 'YYYY')) || NVL(12, TO_CHAR(SYSDATE, 'MM')), 'YYYYMM') AS BASE_MON
FROM
DUAL
)
CONNECT BY
BASE_MON + LEVEL - 1 <= LAST_DAY (BASE_MON)
)
GROUP BY WEEK_GRP
ORDER BY WEEK_GRP
재귀 구조를 갖는 데이터의 경로 출력
CREATE OR REPLACE FUNCTION DEV_IMK.FN_GET_DISP_FULLNM (
ARG_DISP_NO DISPLAY_CLASS.DISP_NO%TYPE,
ARG_DELIMITER VARCHAR2
)
RETURN VARCHAR2 IS
V_DISP_NM VARCHAR2(400);
BEGIN
SELECT MAX(CASE WHEN DISP_DEP = 1 THEN DISP_NM END) ||
MAX(CASE WHEN DISP_DEP = 2 THEN ARG_DELIMITER || DISP_NM END) ||
MAX(CASE WHEN DISP_DEP = 3 THEN ARG_DELIMITER || DISP_NM END) ||
MAX(CASE WHEN DISP_DEP = 4 THEN ARG_DELIMITER || DISP_NM END) ||
MAX(CASE WHEN DISP_DEP = 5 THEN ARG_DELIMITER || DISP_NM END) ||
MAX(CASE WHEN DISP_DEP = 6 THEN ARG_DELIMITER || DISP_NM END)
INTO V_DISP_NM
FROM (
SELECT DISP_NO, DISP_NM, HIGH_DISP_NO, DISP_DEP
FROM DISPLAY_CLASS
WHERE SHOP_NO = ARG_SHOP_NO
AND DISP_NO LIKE SUBSTR(ARG_DISP_NO, 1, 3) || '%' -- 1DEPTH 이하모든전시
)
START WITH DISP_NO = ARG_DISP_NO
CONNECT BY DISP_NO = PRIOR HIGH_DISP_NO
ORDER BY DISP_NO;
RETURN V_DISP_NM;
EXCEPTION
WHEN NO_DATA_FOUND THEN NULL;
WHEN OTHERS THEN RAISE; -- Consider logging the error and then re-raise
END FN_GET_DISP_FULLNM;
/
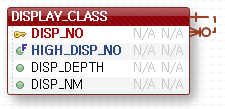
위와 같이 자기 자신을 참조하는 데이터 구조일 때 (보통 분류를 다루는 테이블에서 많이 볼 수 있다.) 하위 데이터를 기준으로 상위 데이터의 경로를 출력하는 프로시저.
가령 데이터가 아래와 같을 때는:
DISP_NO HIGH_DISP_NO DISP_DEPTH DISP_NM
------- ------------ ---------- --------------
101 0 1 최상위
10101 101 2 그다음
1010101 10101 3 그다음다음
이렇게 된다:
SELECT FN_GET_DISP_FULLNM('1010101', ' > ')
FROM DUAL
-> 최상위 > 그다음 > 그다음다음
connect by로 날짜 데이터 만들기
날짜범위 지정
SELECT
TO_CHAR(TO_DATE('20150401','yyyymmdd') + LEVEL - 1, 'yyyymmdd') AS SOLAR_DATE,
TO_CHAR(TO_DATE('20150401','yyyymmdd') + LEVEL - 1, 'D') AS WEEK_DAY
FROM DUAL
CONNECT BY LEVEL <= TO_DATE('20150530','yyyymmdd') - TO_DATE('20150401','yyyymmdd') + 1
오늘 기준 30일 전후
SELECT
TO_CHAR((SYSDATE - 30) + LEVEL - 1, 'yyyymmdd') AS SOLAR_DATE,
TO_CHAR((SYSDATE - 30) + LEVEL - 1, 'D') AS WEEK_DAY
FROM DUAL
CONNECT BY LEVEL <= (SYSDATE + 30) - (SYSDATE - 30) + 1
오늘 기준 마지막 날까지 출력
SELECT SYSDATE + LEVEL -1 AS DAYS
FROM DUAL
CONNECT BY SYSDATE + LEVEL -1 <= LAST_DAY(SYSDATE)
다중 행을 하나의 행으로 출력
다중 행을 하나의 행으로 출력한다. 하나의 컬럼으로 합쳐서 구분자로 표현하는 것이 아니라, 아예 다수의 컬럼으로 쪼개는 방법이다.
이게 무슨말이냐면:
WITH temp1 AS (
SELECT 1001 AS mem_no, '김모양' AS mem_nm FROM dual
),
temp2 AS (
SELECT 1001 AS mem_no, '01' AS tp, '01001' AS tp_value FROM dual
UNION
SELECT 1001 AS mem_no, '02' AS tp, '02002' AS tp_value FROM dual
UNION
SELECT 1001 AS mem_no, '03' AS tp, '03003' AS tp_value FROM dual
)
SELECT temp1.mem_no, mem_nm, tp, tp_value
FROM temp1
JOIN temp2 ON temp1.mem_no = temp2.mem_no
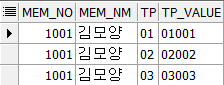
위와 같은 데이터가 있을 때 아래처럼 출력하려고 하는 방법이다.

#1
우선 무식한 방법으로는:
SELECT temp1.mem_no, mem_nm,
tp01.tp_value AS tp01,
tp02.tp_value AS tp02,
tp03.tp_value AS tp03
FROM temp1
JOIN temp2 tp01 ON temp1.mem_no = tp01.mem_no AND tp01.tp = '01'
JOIN temp2 tp02 ON temp1.mem_no = tp02.mem_no AND tp02.tp = '02'
JOIN temp2 tp03 ON temp1.mem_no = tp03.mem_no AND tp03.tp = '03'
#2
위보단 덜 무식한 방법으로 스칼라 쿼리를 이용할 경우:
SELECT temp1.mem_no, mem_nm, (SELECT tp_value FROM temp2 WHERE tp = '01') AS tp01, (SELECT tp_value FROM temp2 WHERE tp = '02') AS tp02, (SELECT tp_value FROM temp2 WHERE tp = '03') AS tp03 FROM temp1
#3
이제 조금 우아하게 CASE문으로 ALIAS를 생성한 뒤 이것을 뷰로 사용하여 GROUP BY를 적용하는 방법이 있다:
SELECT mem_no, mem_nm, MAX(tp01), MAX(tp02), MAX(tp03)
FROM (
SELECT temp1.mem_no, mem_nm,
CASE WHEN TP ='01' THEN tp_value ELSE NULL END AS tp01,
CASE WHEN TP ='02' THEN tp_value ELSE NULL END AS tp02,
CASE WHEN TP ='03' THEN tp_value ELSE NULL END AS tp03
FROM temp1
JOIN temp2 ON temp1.mem_no = temp2.mem_no
) GROUP BY mem_no, mem_nm
단, 이 방법은 최종적으로 출력해야 하는 컬럼의 수가 늘어날 수록 GROUP BY로 포함해야 하는 컬럼 또한 같이 늘어난다는 단점이 있다. 따라서 출력하는 컬럼이 속도에 영향을 줄 정도로 증가한다면 다음과 같은 방법이 고려될 수 있다:
SELECT a.mem_no, mem_nm, tp01, tp02, tp03
FROM temp1 a
JOIN (
SELECT mem_no, MAX(tp01) AS tp01, MAX(tp02) AS tp02, MAX(tp03) AS tp03
FROM (
SELECT mem_no,
CASE WHEN TP ='01' THEN tp_value ELSE NULL END AS tp01,
CASE WHEN TP ='02' THEN tp_value ELSE NULL END AS tp02,
CASE WHEN TP ='03' THEN tp_value ELSE NULL END AS tp03
FROM temp2
)
GROUP BY mem_no
) b ON a.mem_no = b.mem_no
테이블 컬럼을 자바 필드로
SELECT
/*A.TABLE_NAME, A.COLUMN_NAME, B.COMMENTS, A.DATA_TYPE,*/
'/**' || B.COMMENTS || '*/' || 'private '
|| CASE DATA_TYPE
WHEN 'NUMBER' THEN 'Integer'
WHEN 'DATE' THEN 'Date'
ELSE 'String'
END
|| ' ' || A.COLUMN_NAME || '; // ' || A.DATA_TYPE || '('
|| CASE A.DATA_TYPE
WHEN 'NUMBER' THEN A.DATA_PRECISION || ',' || A.DATA_SCALE
ELSE TO_CHAR(A.DATA_LENGTH)
END
|| ')' AS "FIELD"
FROM ALL_TAB_COLUMNS A
JOIN ALL_COL_COMMENTS B ON A.COLUMN_NAME = B.COLUMN_NAME AND A.TABLE_NAME = B.TABLE_NAME
WHERE A.OWNER = 'SOME_OWNER'
AND A.TABLE_NAME = 'SOME_TABLE'
ORDER BY COLUMN_ID;
쿼리로 목록 추출한 다음 할 일:
- 줄 바꿈
- 편집기로 카멜케이스 변환
- 자바 데이터 타입 변경
곁다리: 컬럼 코멘트를 열 머리글(별칭)로
SELECT
"COLS".COLUMN_NAME || ' AS "' || "COMM".COMMENTS || '",'
FROM ALL_TAB_COLUMNS "COLS"
JOIN ALL_COL_COMMENTS "COMM" ON "COLS".TABLE_NAME = "COMM".TABLE_NAME AND "COLS".COLUMN_NAME = "COMM".COLUMN_NAME
WHERE "COLS".TABLE_NAME = 'SOME_TABLE'
ORDER BY "COLS".COLUMN_ID;